Decomposed Prompting Does Not Fix Knowledge Gaps, But Helps Models Say "I Don't Know"
Accepted to Findings of ACL 2026.
This paper asks a deceptively simple question: if we break a hard question into smaller steps, do language models actually become more reliable, or do they just sound more organized while making the same mistakes?
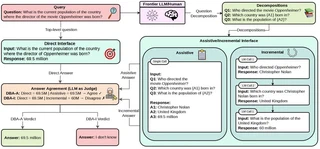
We study this in the setting of closed-book question answering, where the model has to rely on what it already knows rather than external retrieval. While decomposed prompting is often treated as a way to improve reasoning, our results show a more nuanced story: decomposition does not consistently fix underlying knowledge gaps, especially in stronger frontier models. What it does provide is a highly useful diagnostic signal.
Across direct, assistive, and incremental prompting regimes, we find that disagreements between prompting strategies are strongly associated with potential errors. Since genuine factual knowledge tends to stay stable across formulations while hallucinations are much more stochastic, this disagreement becomes a practical indicator of when a model should say “I don’t know.”
Using that observation, we build a training-free abstention policy that does not require retrieval or fine-tuning. The result is a simple but effective method for improving reliability in closed-book QA by helping models abstain more appropriately when they are uncertain.
If you’d like to read the paper, you can find the preprint on arXiv here. The code for the disagreement-based abstention setup is available here.
